|
di Fabio Giglietto
27 Maggio 2005
Da alcuni anni è emersa, nellambito delle discussioni che hanno luogo su Internet, la pratica di utilizzare letichetta
social software per fare riferimento a un crescente
numero di applicazioni orientate a supportare la collaborazione fra gruppi a
distanza. Lesigenza, così come luso delletichetta, non sono nuovi. Da sempre
la rete Internet è stata considerata uno strumento di collaborazione e la storia
della nascita del World Wide Web ideato come un sistema di archiviazione e
condivisione della conoscenza destinato ai ricercatori è un esempio
chiaro di questa natura profonda delle rete. su Internet, la pratica di utilizzare letichetta
social software per fare riferimento a un crescente
numero di applicazioni orientate a supportare la collaborazione fra gruppi a
distanza. Lesigenza, così come luso delletichetta, non sono nuovi. Da sempre
la rete Internet è stata considerata uno strumento di collaborazione e la storia
della nascita del World Wide Web ideato come un sistema di archiviazione e
condivisione della conoscenza destinato ai ricercatori è un esempio
chiaro di questa natura profonda delle rete.
Quello che colpisce
leggendo la storia del web è che, da sempre, i suoi ideatori avessero in mente
uno spazio dove il lettore e lautore fossero entrambi in grado di contribuire
attivamente al processo di sviluppo della conoscenza. Lidea che cè
alla base è quella dellipertesto aperto. Se si pensa un attimo alluso del web
così come noi oggi lo conosciamo, sembra evidente che le cose siano andate in un
altro modo: al web sono state applicate le logiche mediali che tanto gli autori
quanto gli spettatori hanno imparato a conoscere attraverso i mezzi di
comunicazione di massa. La logica del portale multifunzionale, quella della
vendita degli spazi pubblicitari, le offerte di connettività che privilegiano il
canale di download a quello di upload, lattenzione allauditel nella sua
versione riveduta e corretta di audiweb, costituiscono altrettanti
esempi di questo modo di intendere il web come un mezzo di comunicazione a sola
lettura.
Eppure linfrastruttura della rete Internet è
paritetica. Ogni computer collegato, con il suo numero identificativo univoco, è
in grado tanto di ricevere quanto di inviare informazioni. Da pari a
pari. A poco a poco gli utenti se ne sono accorti. Poi è venuto Napster
e la pletora di network peer-to-peer dai quali oggi è possibile scaricare in
poche ore musica, film e programmi televisivi. Oggi i contenuti più scambiati
sono quelli di cui non si detiene il copyright, ma linfrastruttura supporta, al
tempo stesso, la diffusione di contenuti auto-prodotti dagli utenti. Da tempo la
tecnologia per realizzare un film o quella per registrare un album musicale
hanno raggiunto costi e facilità duso impensabili solo pochi anni fa.
Linfrastruttura di Internet rende possibile la distribuzione globale di questi
contenuti presso un'audience potenzialmente mondiale a costi molto bassi.
La disponibilità di uno strumento di pubblicazione come Internet era il
tassello che mancava per realizzare la pulsione al "farsi media". Il
primo mezzo di comunicazione di massa per le masse.
Viene spontaneo
domandarsi  cosa accadrà con la disponibilità di questa enorme massa
di contenuti. In mancanza di filtri allatto della pubblicazione, chi ne
certificherà i contenuti? Come sarà possibile orientarsi verso i
contenti di qualità evitando lo spam dellinformazione? Domande a cui è
difficile rispondere senza scadere nella futurologia. Eppure a ben guardare il
"farsi media" è già oggi. Per ora ha una forma quasi unicamente testuale ma il
caso dei blog può aiutarci a capire dove stiamo andando. Ad
oggi la rete conta circa 10.300.000 diari di bordo con i loro messaggi ed i
relativi commenti. Ogni web-log rimanda ad altri web-log nella forma della
citazione o della esplicita segnalazione. cosa accadrà con la disponibilità di questa enorme massa
di contenuti. In mancanza di filtri allatto della pubblicazione, chi ne
certificherà i contenuti? Come sarà possibile orientarsi verso i
contenti di qualità evitando lo spam dellinformazione? Domande a cui è
difficile rispondere senza scadere nella futurologia. Eppure a ben guardare il
"farsi media" è già oggi. Per ora ha una forma quasi unicamente testuale ma il
caso dei blog può aiutarci a capire dove stiamo andando. Ad
oggi la rete conta circa 10.300.000 diari di bordo con i loro messaggi ed i
relativi commenti. Ogni web-log rimanda ad altri web-log nella forma della
citazione o della esplicita segnalazione.
Alcuni trattano di temi personali
in una forma simile a quella del diario, altri sono tenuti da professionisti del
giornalismo, della tecnologia o della ricerca scientifica. Contenuti
diversissimi e incommensurabili. Per quanto ci riguarda conta tuttavia la forma
più che il contenuto. E la forma è quella tipica di un media di massa.
Ben presto lautore di un blog si trova a pensare ed agire come un
media. Pubblico questo o quellaltro argomento, cosa ne pensano i miei
lettori, come posso far conoscere i miei contenuti ad un numero maggiore di
persone, cosa scrivono negli altri blog
Esistono vere e proprie strategie
di marketing dei propri contenuti e, in fondo, di se stessi. Si tratta tuttavia
di un marketing dove la qualità del contenuto percepito dal lettore è
fondamentale. Come già il web-marketing ha insegnato, una visita
procurata con una pubblicità ingannevole è perfettamente inutile perché si
esaurisce nello spazio dei pochi secondi durante i quali lutente si rende conto
di non essere interessato a quei contenuti.
Si tratta di un
mercato in cui la fiducia è tutto. Decidere in che negozio comprare un
articolo, quale film andare a vedere al cinema o da quale medico rivolgersi per
un certo problema di salute costituiscono classici esempi nei quali facciamo
affidamento alle reti sociali per muoverci nella complessità.
In genere si chiede consiglio a persone verso le quali nutriamo fiducia, se non
altro rispetto al settore specifico di riferimento. E queste ci indirizzano su
persone verso le quali esse nutrono fiducia. Può capitare di chiedere diversi
pareri a ciascuno dei quali attribuiamo più o meno peso a seconda della fiducia
che nutriamo verso le persone che li hanno espressi.
Qualcuno
potrebbe essere sorpreso nel venire a conoscenza che la logica di
funzionamento del motore di ricerca Google, il criterio con il quale
mette in ordine e ci presenta i risultati di una ricerca, si fonda esattamente
su una variante tecnologica dello stesso principio. Il ragionamento che sta alla
base di questo algoritmo di Page Rank è fondato sullassunto che un sito
linkato (e dunque segnalato) da molti altri siti rappresenta una risorsa utile
per la comunità. Ma non tutti i link contano allo stesso modo. Un link al mio
sito proveniente da un sito che a sua volta ha molti collegamenti in entrata (ha
dunque una buona reputazione) è considerato più pesante di un link proveniente
da un sito con pochi collegamenti in ingresso.
Una cosa simile
avviene con i blog. In genere si inizia da un blog di fiducia. Magari
una persona che si conosce personalmente, un collega o un amico. Poi si inizia a
visitare i blog che il nostro conoscente cita più di frequente. Poi quelli
citati più di frequente da quelli citati dal nostro conoscente. In breve tempo
ci si ritrova a leggere un numero significativo di post al giorno. Nel tempo
libero, come quando si legge il giornale. Solo che in questo caso i contenuti
che leggiamo riguardano degli argomenti di nostro specifico interesse e sono
prodotti, in gran parte, da non professionisti.
La logica è la stessa
della reti sociali  che
ben conosciamo. Quello che cambia è la scala. Più persone partecipano a
questo gioco di selezione collaborativa dei contenuti, più il gioco funziona
bene. Più il gioco funziona bene, maggiore è la quantità di contenuti
che si possono controllare. Su questo stesso modello esistono numerosi altri
esempi fondati sulla classificazione sociale o collaborativa dei contenuti.
La pratica di etichettare i contenuti del web è parzialmente simile ad
una recensione ridotta ai minimi termini. Il fatto che gli utenti
abbiano fatto lo sforzo di etichettare un certo contenuto dovrebbe far supporre
che si tratta di una risorsa in qualche modo valida rispetto alla categoria
nella quale è stata classificata. Si tratta dunque di una forma di knowledge
management distribuito. Come tutte le attività che sorgono spontaneamente
nella forma dellauto-organizzazione, anche la classificazione sociale dei
contenuti ha la sua potenza ed il suo limite nellauto-coordinamento. Non esiste
una entità esterna che possa decidere della qualità della classificazione, e
questo che
ben conosciamo. Quello che cambia è la scala. Più persone partecipano a
questo gioco di selezione collaborativa dei contenuti, più il gioco funziona
bene. Più il gioco funziona bene, maggiore è la quantità di contenuti
che si possono controllare. Su questo stesso modello esistono numerosi altri
esempi fondati sulla classificazione sociale o collaborativa dei contenuti.
La pratica di etichettare i contenuti del web è parzialmente simile ad
una recensione ridotta ai minimi termini. Il fatto che gli utenti
abbiano fatto lo sforzo di etichettare un certo contenuto dovrebbe far supporre
che si tratta di una risorsa in qualche modo valida rispetto alla categoria
nella quale è stata classificata. Si tratta dunque di una forma di knowledge
management distribuito. Come tutte le attività che sorgono spontaneamente
nella forma dellauto-organizzazione, anche la classificazione sociale dei
contenuti ha la sua potenza ed il suo limite nellauto-coordinamento. Non esiste
una entità esterna che possa decidere della qualità della classificazione, e
questo
dunque non impedisce che in linea teorica qualcuno classifichi
qualcosa deliberatamente sotto una etichetta sbagliata. Anche il controllo della
qualità si esprime in questi ambiente in una forma non gerarchica ma
distribuita, che ricorda la pratica delle peer review degli articoli scientifici
in ambito accademico.
Particolarmente interessante in questo senso è il
caso dellenciclopedia collaborativa Wikipedia e - in una forma ancora più evidente - il caso
dellesperimento di giornalismo collaborativo denominato Wikinews. Nato da una costola di
Wikipedia, Wikinews sfrutta la stessa logica distribuita per la
realizzazione di un sito collettivo di news. Lidea è che essendo
Internet una struttura distribuita sul territorio mondiale, sia ragionevole
pensare di trovare qualcuno che possa raccontare i fatti da una prospettiva
ravvicinata senza appoggiarsi alle agenzie di stampa. Ovviamente, come nel caso
dellenciclopedia, il fatto che tutti possano in linea teorica partecipare non
significa che tutto possa essere pubblicato. Per questo motivo il
controllo di qualità è affidato ad altri partecipanti al
progetto che contribuiscono alla causa da questa diversa prospettiva. Alla prova
dei fatti questa strategia della peer review si è dimostrata, almeno
fino a questo momento, alquanto macchinosa e non sempre efficace. Se i tempi di
pubblicazione o di revisione di un lemma di una enciclopedia possono essere
ragionevolmente dilatati nel tempo, altrettanto non si può dire per una notizia,
che perde gran parte del suo valore se comunicata troppo tardi. Sul piano della
qualità dei contenuti, invece, alcune imprecisioni sono state fatte notare da
esponenti della comunità accademica. Sia nel caso delle notizie, sia in quello
dellenciclopedia, emerge il problema del rapporto con la verità. Mentre
tuttavia il giornalismo (ed il sistema dei media in generale) ha da tempo
risolto questo problema demandandolo ad una forma di etica interna al sistema
e dunque a una forma di auto-controllo affidato alla gerarchia (il direttore di
testata, di rete, etc.) e ai giornalisti stessi, altrettanto non si può dire di
una enciclopedia. In questo ultimo caso il rapporto con la verità è demandato
alla comunità accademica cui è affidato il compito di dire cosa è vero e cosa
non lo è in campo scientifico. In questo senso, mentre Wikinews potrà riproporre
la forma di auto-controllo propria del sistema dei media, Wikipedia sarà sempre
soggetta al giudizio finale sulla qualità dei propri articoli intesa come
aderenza o meno alle verità di volta in volta proposte dal sistema della
scienza.
Oltre al controllo di qualità esistono anche altri problemi
intrinseci dei sistemi basati sullauto-organizzazione collaborativa.
Nel caso delletichettamento dei contenuti, infatti, emerge evidente il
problema dei sinonimi, dei plurali e delle etichette non culturalmente
neutrali. Dietro la stessa etichetta potrebbero infatti nascondersi
significati (e quindi contenuti) diversi a seconda dellosservatore. Allo stesso
modo le categorie "gatto" e "gatti" rendono necessario cercare in due categorie
diverse invece che in un una. Così anche "animali" potrebbe contenere proprio la
foto del gatto che stavo cercando. Questo senza entrare nelle differenti
interpretazioni culturali di una certa etichetta (si pensi ad esempio ai
colori). La struttura delle etichette è piatta e, non essendo stata
pianificata a priori, i margini semantici di una categoria tendono a confondersi
e sovrapporsi con quelli delle altre. Proprio in relazione a questa
strutturale indeterminatezza, è stato coniato il termine di "semantiche
emergenti" per contrapporre questo tipo di sistemi di classificazione a
quelli dove le categorie semantiche sono fissate allinizio e dallalto. Si
pensi ad esempio ai sistemi di classificazione delle biblioteche o alle
directory gerarchiche di contenuti come Yahoo!. Spesso, inoltre, queste forme di semantiche emergenti
sono osservate in opposizione più o meno palese rispetto al progetto del Web
Semantico ideato da Tim Berners Lee. Lultima visione dellinventore del World
Wide Web prevede infatti alla propria base lesistenza di "ontologie
web", ovvero descrizioni formali di certe aree del sapere o domini
concettuali progettate per essere consistenti e non contraddittorie.
Un'ontologia deve essere progettata da qualcuno ed accettata da tutti gli altri
affinché sia efficace. basati sullauto-organizzazione collaborativa.
Nel caso delletichettamento dei contenuti, infatti, emerge evidente il
problema dei sinonimi, dei plurali e delle etichette non culturalmente
neutrali. Dietro la stessa etichetta potrebbero infatti nascondersi
significati (e quindi contenuti) diversi a seconda dellosservatore. Allo stesso
modo le categorie "gatto" e "gatti" rendono necessario cercare in due categorie
diverse invece che in un una. Così anche "animali" potrebbe contenere proprio la
foto del gatto che stavo cercando. Questo senza entrare nelle differenti
interpretazioni culturali di una certa etichetta (si pensi ad esempio ai
colori). La struttura delle etichette è piatta e, non essendo stata
pianificata a priori, i margini semantici di una categoria tendono a confondersi
e sovrapporsi con quelli delle altre. Proprio in relazione a questa
strutturale indeterminatezza, è stato coniato il termine di "semantiche
emergenti" per contrapporre questo tipo di sistemi di classificazione a
quelli dove le categorie semantiche sono fissate allinizio e dallalto. Si
pensi ad esempio ai sistemi di classificazione delle biblioteche o alle
directory gerarchiche di contenuti come Yahoo!. Spesso, inoltre, queste forme di semantiche emergenti
sono osservate in opposizione più o meno palese rispetto al progetto del Web
Semantico ideato da Tim Berners Lee. Lultima visione dellinventore del World
Wide Web prevede infatti alla propria base lesistenza di "ontologie
web", ovvero descrizioni formali di certe aree del sapere o domini
concettuali progettate per essere consistenti e non contraddittorie.
Un'ontologia deve essere progettata da qualcuno ed accettata da tutti gli altri
affinché sia efficace.
Da questo punto di vista le ontologie web
si contrappongono alle folksonomie. Queste ultime, essendo costruite
dal basso, emergono dall'attività dei singoli utenti e non necessitano dunque di
nessun accordo preventivo. Uscendo dalla logica della contrapposizione diretta è
possibile interpretare questi due sistemi di classificazione all'apparenza
mutuamente esclusivi secondo una linea di continuità che considera le semantiche
emergenti proprie delle folksonomie come versioni leggere - meno strutturate -
delle ontologie.
Una soluzione elegante di superamento di questo
dualismo sta nell'idea della folktology.
Si tratta di consentire
alla comunità degli utenti non sono di classificare i contenuti secondo uno
schema semantico dato (una ontologia), ma di poter modificare le classi che
costituiscono gli schemi premiando o punendo con un sistema di
credito/discredito le classificazioni più o meno utilizzate dalla comunità. Una
specie di logica evolutiva dellontologia. Allo stesso modo, se esistesse un
sistema semplice per poter creare una propria ontologia personale (in fondo è
quello che tutti facciamo quando classifichiamo i nostri documenti nelle
cartelle del file system di Windows) e per condividerla, si potrebbero veramente
creare degli interessanti software sociali di classificazione che possano unire
il rigore delle ontologie con la logica dal basso e democratica delle
folksonomie.
Ma cè dellaltro. Mentre servono per selezionare,
queste reti di relazioni fatte di collegamenti ipertestuali ci
raccontano qualcosa sui nostri gusti e sulle tendenze. Diventa quindi
possibile, ad esempio, osservarci nello specchio di Google per leggervi lo spirito del
tempo. Si scopre così che la keyword "tsunami" ha primeggiato nel mese di
gennaio 2005 superando persino leterna regina delle ricerche web Britney
Spears. Allo stesso modo, dando uno sguardo alle etichette usate dagli utenti
per catalogare le fotografie digitali pubblicate sul servizio Flikr, possiamo concludere che
gli utenti del sito tendono a fotografare più i gatti (26.626 fotografie) che i
cani (22.988).
Esiste un'intera classe di software sociali
dedicati alletichettamento collaborativo di 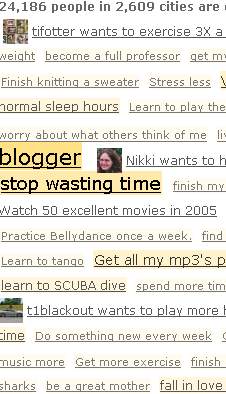 contenuti. Applicando unetichetta ad un certo
sito Internet posso creare delle directory di risorse disponibili in rete: forse
meno strutturate di quella di Yahoo!, ma non per questo meno utili. Funziona in
questo modo del.icio.us che si
presenta proprio come un sistema di bookmark sociale. Anche in questo caso posso
farmi unidea di questa comunità guardando le etichette più popolari. La prima è
"blog" seguita da "software" e da "web". Non è difficile concludere anche sulla
base di uno sguardo molto superficiale che molti degli utenti di del.icio.us
sono anche blogger e che comunque, in media, il servizio attiri un pubblico di
utenti spesso professionisti dellinformatica o interessati ai temi
dellinformatica. Su questa caratteristica gioca anche 43 Things, nel quale lutente
deve segnalare un certo numero di cose (fino a 43 appunto) che intende portare a
termine. Un elenco di buoni propositi sul modello di quelli che si fanno
allinizio di un nuovo anno. Una volta stilato il proprio elenco, il sistema
provvede a mettere in contatto diretto gli altri che condividono gli stessi
obiettivi. Ci si può scambiare consigli o farsi coraggio a vicenda. Uno sguardo
aggregato ci porta a scoprire che la cosa che più di tutte rientra fra gli
obiettivi indicati è innamorarsi. Riuscite a pensare ad un modo migliore di
innamorarsi che frequentare una comunità che condivide con noi questo preciso
scopo nella vita? contenuti. Applicando unetichetta ad un certo
sito Internet posso creare delle directory di risorse disponibili in rete: forse
meno strutturate di quella di Yahoo!, ma non per questo meno utili. Funziona in
questo modo del.icio.us che si
presenta proprio come un sistema di bookmark sociale. Anche in questo caso posso
farmi unidea di questa comunità guardando le etichette più popolari. La prima è
"blog" seguita da "software" e da "web". Non è difficile concludere anche sulla
base di uno sguardo molto superficiale che molti degli utenti di del.icio.us
sono anche blogger e che comunque, in media, il servizio attiri un pubblico di
utenti spesso professionisti dellinformatica o interessati ai temi
dellinformatica. Su questa caratteristica gioca anche 43 Things, nel quale lutente
deve segnalare un certo numero di cose (fino a 43 appunto) che intende portare a
termine. Un elenco di buoni propositi sul modello di quelli che si fanno
allinizio di un nuovo anno. Una volta stilato il proprio elenco, il sistema
provvede a mettere in contatto diretto gli altri che condividono gli stessi
obiettivi. Ci si può scambiare consigli o farsi coraggio a vicenda. Uno sguardo
aggregato ci porta a scoprire che la cosa che più di tutte rientra fra gli
obiettivi indicati è innamorarsi. Riuscite a pensare ad un modo migliore di
innamorarsi che frequentare una comunità che condivide con noi questo preciso
scopo nella vita?
Le realtà emergenti dalle operazioni di questi
software sociali sono accomunate da una tendenza che è possibile riscontrare
anche in altri ambiti del web. In genere esistono quasi sempre poche
etichette estremamente affollate e un numero sterminato di etichette poco o
nulla utilizzate. Questo dato fa il paio con quello che riguarda il
numero di post in un blog, e i link in ingresso. Anche in questo caso si assiste
a fenomeni di concentrazione estremamente significativi e regolari che hanno
fatto parlare qualcuno di una vera e propria "legge del
web".
Aprire il proprio blog è una pratica piuttosto
comune nelle scuole.
Si tratta di software gratuti per la
pubblicazione dei contenuti sul web piuttosto semplici da utilizzare, che ci
mettono in poche mosse di fronte ad un'audience potenzialmente globale. Lidea
di essere osservati è implicita nel blog. Da questo punto di vista è evidente il
paradosso fra una struttura narrativa simile a quella del diario personale e la
natura pubblica di questi spazi. Ma quello che qui interessa è il fatto
che il blog implichi lidea di un pubblico.
Gestire un
blog equivale a entrare nella logica delle comunicazioni di massa dal punto di
vista di chi comunica. Si tratta di un'esperienza inedita che ha
notevoli conseguenze sul piano epistemologico. Il pubblico di un blog è
indistinto come lo è quello tipico dei mass media. Può farsi vivo e dire la sua
opinione usando lo spazio riservato nei commenti, ma questo non fa che ribadire
un'asimmetria strutturale fra il padrone di casa e gli ospiti. La presenza di un
pubblico (o lidea che un pubblico potrebbe essere presente) evoca lidea di un
dialogo fra due. Io e il mio pubblico. Ma questo pubblico
astratto, etereo e generalizzato non è nullaltro che lidea concretizzata della
consapevolezza della presenza nellambiente di altri osservatori.
Quando il
numero di osservatori potenziali eccede le mia capacità di considerarli nella
loro singolarità compare il concetto di pubblico come insieme
indistinto.
Le caratteristiche del mio pubblico in quanto insieme
di osservatori eterogeneo sono indistinte ed un po sfumate, ma non possono
esserlo troppo da impedirmi di fare delle scelte sulla base dellidea che mi
sono costruito del mio pubblico. Pienamente dentro la logica dei mass media
inizio a ritenere di conoscere il mio pubblico e agisco di conseguenza. In
questo modo il dialogo si trasforma in un monologo fra me ed la mia idea
del mio pubblico. Questa chiusura autoreferenziale non è una
degenerazione del sistema dei mass media, ma una sua caratteristica strutturale
e ineliminabile che ha a che fare con il fatto che losservatore (il sistema dei
mass media) non può conoscere la vera natura del suo pubblico.
Fare
esperienza di questa
prospettiva è un'opportunità straordinaria che si concretizza grazie alla
contemporanea disponibilità di mezzi di produzione (videocamere, fotocamere,
registratori digitali) e di diffusione globale (la rete Internet) vastamente
accessibili. Ma le ricadute non si limitano al rapporto con i mezzi di
comunicazione di massa. Nellusare le logiche dei media impariamo ad
usare in modo critico la distinzione auto/etero-referenza. Si tratta di
un processo di osservazione di osservazioni e specificamente di una
auto-osservazione. Loperazione di auto-osservazione è centrale nello sviluppo
di una capacità critica sul proprio modo di osservare e dunque di relazionarsi
con gli altri.
Nellambito di un quadro teorico come quello proposto non è
infatti possibile esternalizzare totalmente la causa di un fallimento,
di una relazione interpersonale difficile o
di una classe che non apprende. Ogni etero-riferimento è
infatti da porre in relazione con limmagine delletero che ci siamo costruiti.
Ogni etero-riferimento, dunque, rimanda implicitamente a un auto-riferimento.
È troppo facile dare la colpa agli altri senza pensare in primis a qual
è il nostro contributo personale al fallimento. Prendere coscienza di
questo stato di ineliminabile auto-riferimento dei sistemi viventi e dei nostri
processi cognitivi pone le basi per una più corretta apertura verso lesterno.
Questo nuovo modo di guardare a noi e agli altri ci porta ad apprezzare
laccordo come un improbabile caso di successo nel coordinamento di sistemi
operativamente chiusi. Allo stesso dovrebbe cambiare il modo di guardare
allinsegnamento. Attraverso lesperienza del farsi media è infatti possibile
interiorizzare le logiche dellapprendimento proprie di un mondo dove la
conoscenza e linformazione si costruiscono e non si
trasferiscono. di un quadro teorico come quello proposto non è
infatti possibile esternalizzare totalmente la causa di un fallimento,
di una relazione interpersonale difficile o
di una classe che non apprende. Ogni etero-riferimento è
infatti da porre in relazione con limmagine delletero che ci siamo costruiti.
Ogni etero-riferimento, dunque, rimanda implicitamente a un auto-riferimento.
È troppo facile dare la colpa agli altri senza pensare in primis a qual
è il nostro contributo personale al fallimento. Prendere coscienza di
questo stato di ineliminabile auto-riferimento dei sistemi viventi e dei nostri
processi cognitivi pone le basi per una più corretta apertura verso lesterno.
Questo nuovo modo di guardare a noi e agli altri ci porta ad apprezzare
laccordo come un improbabile caso di successo nel coordinamento di sistemi
operativamente chiusi. Allo stesso dovrebbe cambiare il modo di guardare
allinsegnamento. Attraverso lesperienza del farsi media è infatti possibile
interiorizzare le logiche dellapprendimento proprie di un mondo dove la
conoscenza e linformazione si costruiscono e non si
trasferiscono.
Fabio Giglietto - blog: http://nextmedia.blogspot.com
Ricercatore
LaRiCA
Facoltà di Sociologia
Università di Urbino Carlo Bo
|


